Influxdb oss v2版本-增量数据每日备份与恢复方案设计
1. 方案概述
本方案提供了一套完整的 InfluxDB OSS v2版本数据库异地增量备份与恢复机制,通过在生产环境和恢复环境分别部署 Docker 容器,利用云服务商oss对象存储实现跨地域数据备份和快速故障切换。该方案旨在确保时序数据的安全性、完整性和高可用性,同时优化存储空间利用率。
关联代码: https://github.com/lizhenwei/influxdb_backup_daily
方案目标
- 建立可靠的数据异地备份机制,防止生产环境数据丢失,
- 可按日期进行恢复,若出现故障可回滚至最多14天前的数据
- 实现跨地域的备份恢复流程,支持快速故障切换
- 管理数据生命周期,平衡存储成本与数据保留需求
- 提供灵活的配置选项,适应实际业务场景需求
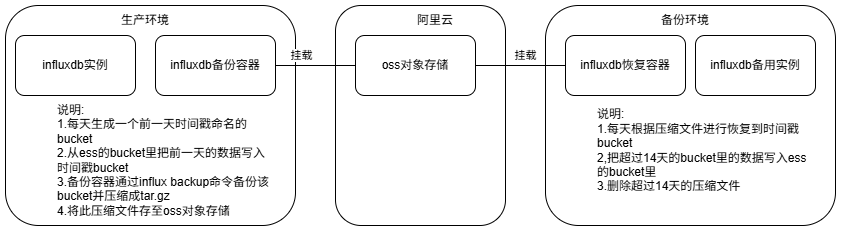
2. 架构设计
本方案采用双环境容器化设计,生产环境部署备份容器,备份地域部署恢复环境运行恢复容器,两者通过云服务商提供的对象存储共享备份数据。
当出现故障时,把备份环境的influxdb数据库目录完整复制到生产环境上,然后决定恢复到那一天
3. 核心功能
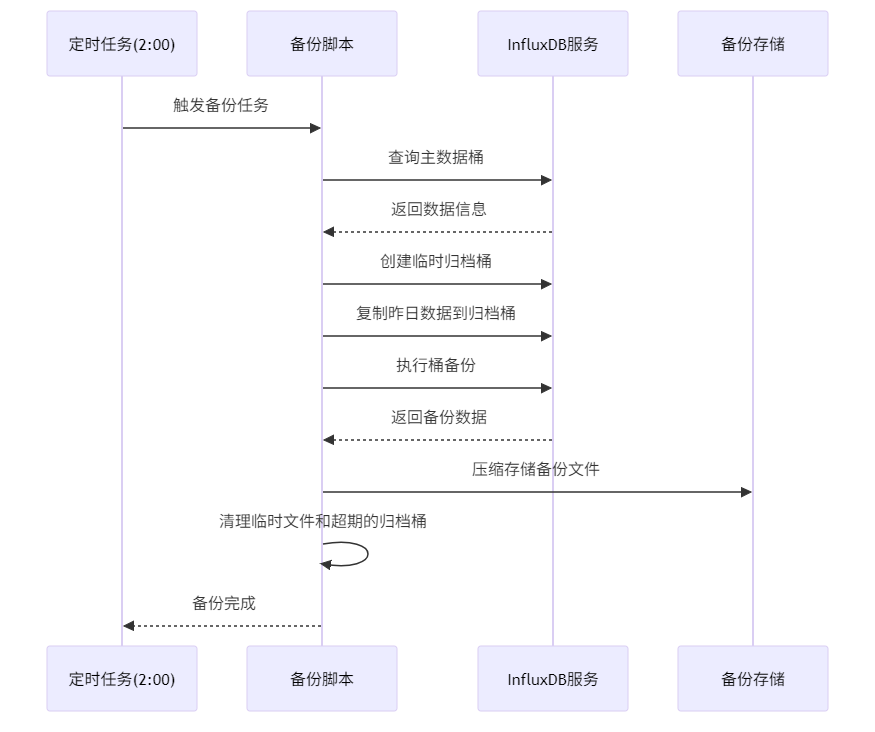
3.1 生产环境每日增量备份
备份流程自动执行,每日捕获前一天的增量数据并存储为压缩文件.
3.1.1 关键代码
# -----------------------
# 复制昨天的数据到新 bucket
# -----------------------
influx query \
--org "$ORG" \
--host "$HOST" \
--token "$TOKEN" \
"from(bucket:\"$SOURCE_BUCKET\")
|> range(start: ${YESTERDAY}T00:00:00Z, stop: ${YESTERDAY}T23:59:59Z)
|> to(bucket:\"$BUCKET\")"
# -----------------------
# 备份 bucket
# -----------------------
mkdir -p "$BACKUP_DIR"
influx backup \
"$BACKUP_DIR" \
--bucket "$BUCKET" \
--org "$ORG" \
--host "$HOST" \
--token "$TOKEN"3.1.2 时序图
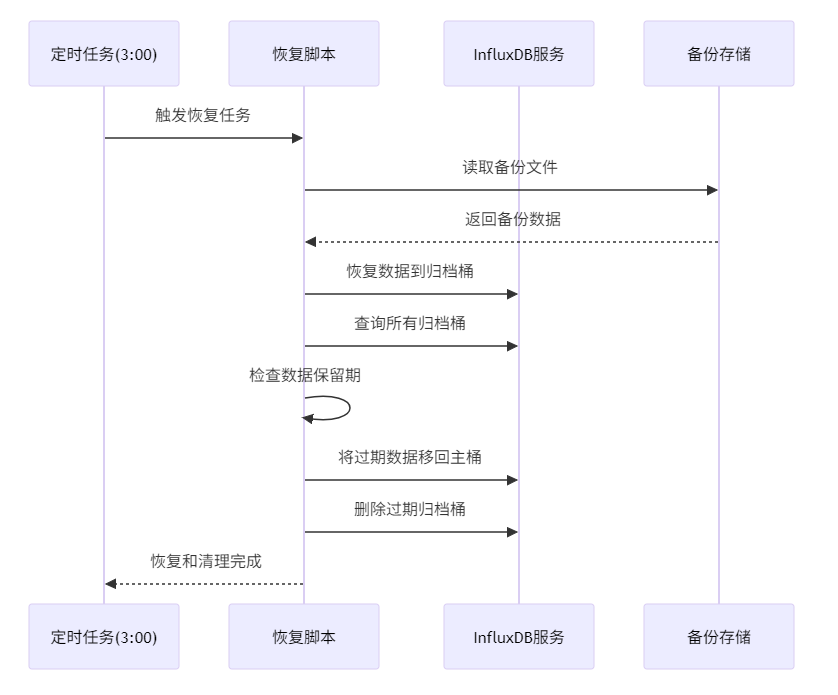
3.2 备份环境-自动恢复与数据生命周期管理
恢复流程包括数据恢复,和数据生命周期管理.有一个主存储桶mani_bucket和最近14天的归档桶.可根据需求将最近14天的数据回写进主存储桶
3.2.1 关键代码
# -----------------------
# 恢复数据
# -----------------------
influx restore \
--bucket "$ARCHIVE_BUCKET" \
--new-bucket "$ARCHIVE_BUCKET" \
--org "$ORG" \
--host "$HOST" \
--token "$TOKEN" \
"$RESTORE_DIR"
# -----------------------
# 超期数据管理
# -----------------------
# 获取所有归档 bucket 列表(名字以archive_开头的)
ARCHIVE_BUCKETS=$(influx bucket list --org "$ORG" --host "$HOST" --token "$TOKEN" --json | jq -r '.[] | select(.name | startswith("archive_")) | .name' | sort)
# 计算超过保留天数的日期阈值
# 使用兼容BusyBox的方式计算:当前时间戳减去保留天数×86400秒
THRESHOLD_DATE=$(date -d @$(($(date +%s) - ${MAX_RETENTION_DAYS}*86400)) +%s)
# 处理每个归档 bucket
for BUCKET in $ARCHIVE_BUCKETS; do
# 从 bucket 名称提取日期
BUCKET_DATE=$(echo "$BUCKET" | sed 's/^archive_//')
# 将日期转换为时间戳进行比较
# 注意:BusyBox的date命令支持直接解析YYYY-MM-DD格式
BUCKET_TIMESTAMP=$(date -d "$BUCKET_DATE" +%s 2>/dev/null)
if [ $? -eq 0 ] && [ $BUCKET_TIMESTAMP -lt $THRESHOLD_DATE ]; then
echo "处理过期数据: $BUCKET ($BUCKET_DATE)"
# 将数据插回主 bucket
echo "将 $BUCKET 的数据插回主 bucket $MAIN_BUCKET"
influx query \
--org "$ORG" \
--host "$HOST" \
--token "$TOKEN" \
"from(bucket:\"$BUCKET\")
|> range(start: 0)
|> to(bucket:\"$MAIN_BUCKET\")"
# 删除过期的 bucket
echo "删除过期的 bucket: $BUCKET"
influx bucket delete \
--name "$BUCKET" \
--org "$ORG" \
--host "$HOST" \
--token "$TOKEN"
fi 3.2.2 时序图
4. 技术选型
| Alpine Linux | 3.22 | 容器基础镜像 | 体积小(约5MB)、启动快、资源占用低 |
| InfluxDB CLI | 2.7.5 | 数据操作工具 | 官方工具,支持完整的数据备份与恢复功能 |
| Docker | 最新版 | 容器化部署 | 环境隔离、易于部署和管理、跨平台兼容性好 |
| Bash | 最新版 | 脚本语言 | 轻量级、广泛支持、适合自动化任务 |
| Cron | 最新版 | 定时任务调度 | 稳定可靠、配置简单、适合周期性任务 |
5. 环境变量配置
Docker容器的环境变量配置,根据环境灵活调整:
ORG_NAME | my-org | InfluxDB 组织名称 |
MAIN_BUCKET_NAME | my-bucket | 主数据桶名称 |
INFLUX_TOKEN | 无 | InfluxDB 访问令牌 |
INFLUX_HOST | http://localhost:8086 | InfluxDB 服务器地址 |
BACKUP_DIR | /backup | 备份文件存储目录 |
MAX_RETENTION_DAYS | 14 | 最多保留archive_bucket天数 |
6.故障恢复流程
1.切换到备份环境供生产使用
2.使用influxdb backup 把备份环境数据整库复制出来
3.拷贝到生产环境
4.使用influxdb restore –full恢复整库生产环境数据
5.切换数据库到生产环境
6.把切库这段时间缺失的数据从备份环境复制到生产环境
7. 风险与应对
| 云服务商云对象存储故障 | 备份数据不可用或丢失 | 1.配置云存储多副本机制 |
| 跨地域网络延迟或中断 | 备份和恢复操作失败或延迟 | 1. 配置监控,及时发现和解决问题 2. 避开网络使用高峰期 |
| 生产环境硬件资源不足 | 备份造成资源不足影响生产使用 | 1.调整备份执行时间,避开使用高峰期 |
| 生产环境与恢复环境数据不一致 | 故障切换后数据丢失 | 1. 确保备份和恢复脚本正确执行 2. 定期验证备份数据的完整性和可恢复性 3. 配置数据同步监控,及时发现数据不一致问题 |
| InfluxDB 服务不可用 | 备份和恢复操作失败 | 1. 监控 InfluxDB 服务状态,设置告警机制 2. 定期进行服务健康检查 |
| 访问令牌泄露 | 数据安全风险 | 1. 遵循最小权限原则,为备份和恢复操作分配适当权限 2. 定期更换访问令牌 3. 使用密钥管理服务存储敏感凭证 4. 不在不安全的地方存储令牌 |
| Docker 容器故障 | 备份和恢复计划中断 | 1. 监控容器运行状态,设置自动重启策略 2. 配置容器健康检查 3. 定期更新容器镜像和基础系统 |
| 只备份前一天的数据,不备份当前数据 | 遇到故障时,当天的数据无法恢复 | 1.只能从sdlink的timescaledb数据里想办法,写代码恢复到influxdb里了 2.或者使用influx remote 和influx replication做双写,但是这样就需要再有一个inflxudb实例.需要增加云服务器成本 |