背景
最近想学习一下elasticsearch和fluentd的配合使用, fluentd比logstash节省太多资源了,所以就有了如下文章
Elasticsearch快捷安装(使用ECK方式)
参考文章
https://www.elastic.co/guide/en/cloud-on-k8s/1.8/k8s-deploy-eck.html
先安装一个eck的operator
kubectl create -f https://download.elastic.co/downloads/eck/1.8.0/crds.yaml
kubectl apply -f https://download.elastic.co/downloads/eck/1.8.0/operator.yaml等命令介绍,输入下面命令查看日志
kubectl -n elastic-system logs -f statefulset.apps/elastic-operator
安装elasticsearch
cat <<EOF | kubectl apply -f -
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: quickstart
spec:
version: 7.15.2
nodeSets:
- name: default
count: 1
config:
node.store.allow_mmap: false
EOF安装完成后,输入命令,获得es的密码,默认账户是elastic
PASSWORD=$(kubectl get secret quickstart-es-elastic-user -o go-template='{{.data.elastic | base64decode}}')
部署完毕后,可以通过port-forward转发elasticsearch的端口到外部进行测试
kubectl port-forward service/quickstart-es-http 9200
再安装一个kibana
cat <<EOF | kubectl apply -f -
apiVersion: kibana.k8s.elastic.co/v1
kind: Kibana
metadata:
name: quickstart
spec:
version: 7.15.2
count: 1
elasticsearchRef:
name: quickstart
EOF可以通过port-forward转发kibana的端口到外部进行测试
kubectl port-forward service/quickstart-kb-http 5601
fluentd安装
编写一个fluentd.yaml ,
编写完毕后kubectl apply -f fluentd.yaml 。内容如下,注意替换密码:
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-logging
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "quickstart-es-http.default.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENT_ELASTICSEARCH_USER
value: "elastic"
- name: FLUENT_ELASTICSEARCH_PASSWORD
value: "我是密码!注意替换"
- name: FLUENT_ELASTICSEARCH_SSL_VERSION
value: "TLSv1_2"
- name: FLUENTD_SYSTEMD_CONF
value: disable
- name: FLUENT_UID
value: "0"
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers部署一个测试程序(用完之后可以删除)
kubectl -n logging apply -f - <<"EOF"
apiVersion: apps/v1
kind: Deployment
metadata:
name: log-generator
spec:
selector:
matchLabels:
app.kubernetes.io/name: log-generator
replicas: 1
template:
metadata:
labels:
app.kubernetes.io/name: log-generator
spec:
containers:
- name: nginx
image: banzaicloud/log-generator:0.3.2
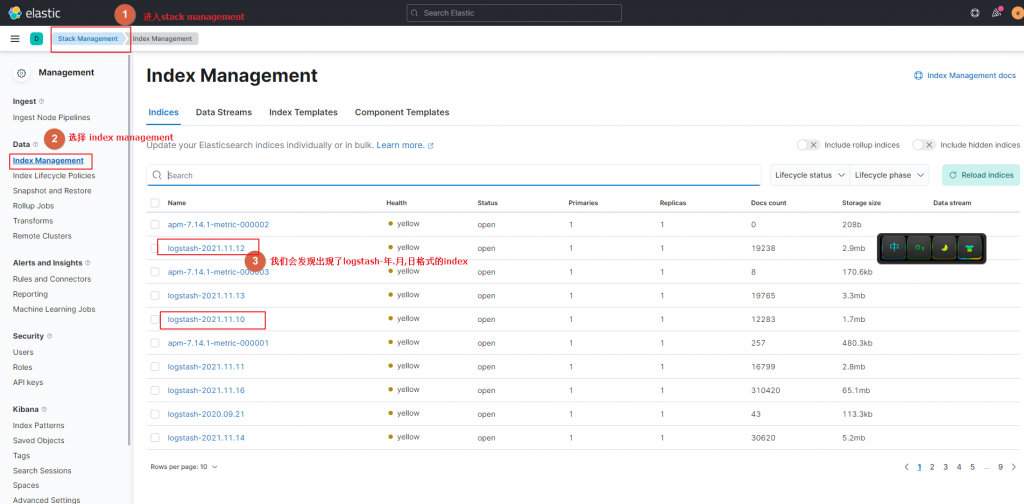
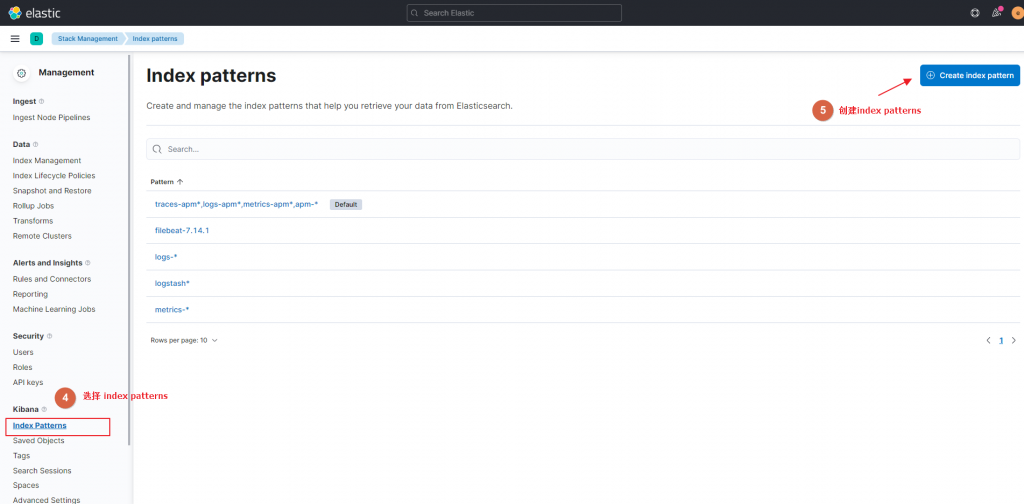
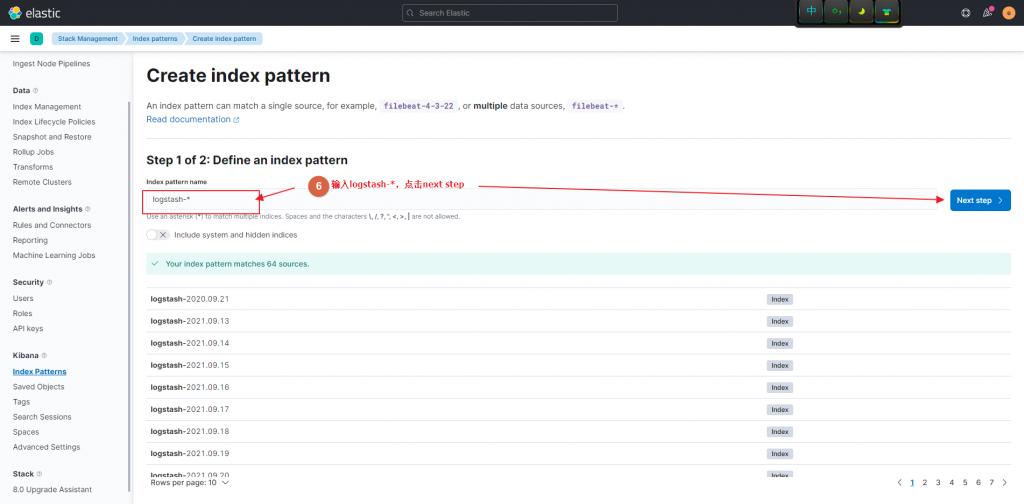
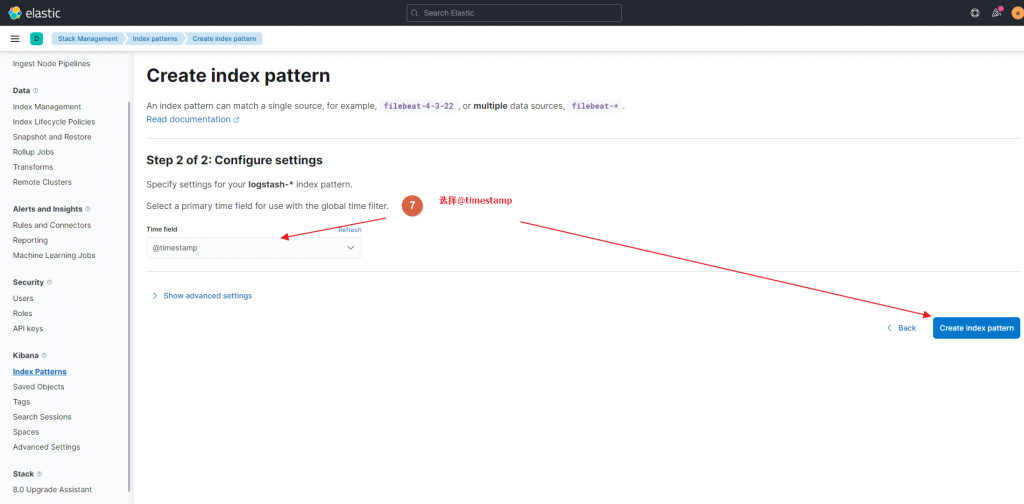
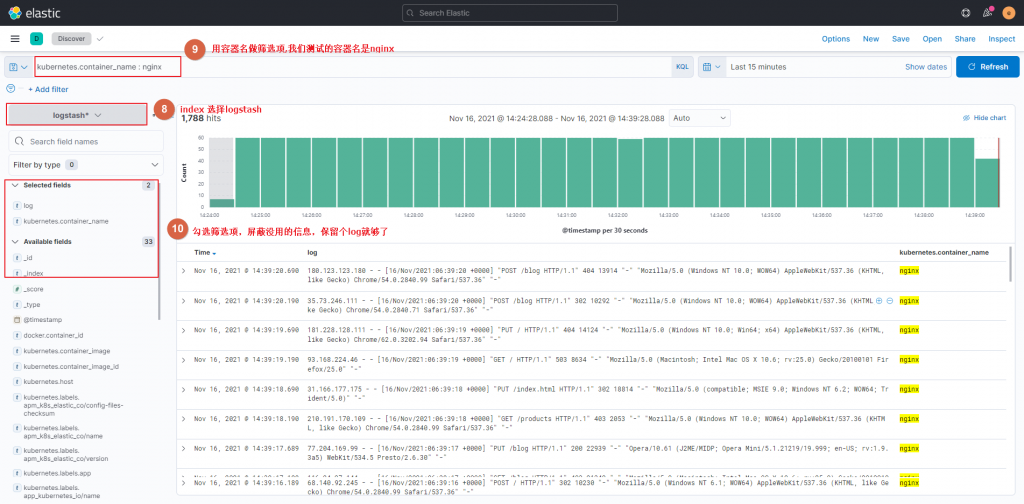
EOFkibana里添加index和查看
直接看图说话
参考文章
https://www.digitalocean.com/community/tutorials/how-to-set-up-an-elasticsearch-fluentd-and-kibana-efk-logging-stack-on-kubernetes
https://docs.fluentd.org/output/elasticsearch
https://github.com/fluent/fluentd-kubernetes-daemonset
https://medium.com/kubernetes-tutorials/cluster-level-logging-in-kubernetes-with-fluentd-e59aa2b6093a