任务目标
以前都是用helm安装elasticsearch,最近发现elasticsearch推荐使用ECK在K8S上安装,那我们就来试试吧
我们会在已有的K8S上安装ECK,elasticsearch,kibana,apm,关闭ssl,loadbalancer暴露应用访问
测试golang接入apm
ECK创建过程
1.先安装上operator
kubectl create -f https://download.elastic.co/downloads/eck/1.7.1/crds.yaml
kubectl apply -f https://download.elastic.co/downloads/eck/1.7.1/operator.yaml2.安装elasticsearch
cat <<EOF | kubectl apply -f -
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: quickstart
spec:
version: 7.14.1
nodeSets:
- name: default
count: 1
config:
node.store.allow_mmap: false
EOF3.安装kibana
cat <<EOF | kubectl apply -f -
apiVersion: kibana.k8s.elastic.co/v1
kind: Kibana
metadata:
name: quickstart
spec:
version: 7.14.1
count: 1
elasticsearchRef:
name: quickstart
EOF4.安装apm
cat <<EOF | kubectl apply -f -
apiVersion: apm.k8s.elastic.co/v1
kind: ApmServer
metadata:
name: apm-server-quickstart
namespace: default
spec:
version: 7.14.1
count: 1
elasticsearchRef:
name: quickstart
EOF5.暴露kibana可外部访问,并且关闭ssl
kubectl edit kibanas.kibana.k8s.elastic.co quickstart。这里只贴上关键的spec部分代码
spec:
count: 1
elasticsearchRef:
name: quickstart
enterpriseSearchRef:
name: ""
http:
service:
metadata: {}
spec:
type: LoadBalancer
tls:
selfSignedCertificate:
disabled: true
6.暴露apm可外部访问
kubectl edit apmserver.apm.k8s.elastic.co/apm-server-quickstart
修改的内容与上面kibana修改内容一致。
7.获取kibana登录用户名和密码
默认用户名 elastic
默认密码使用如下命令获取
kubectl get secret quickstart-es-elastic-user -o go-template='{{.data.elastic | base64decode }}'8.获取apm-server的secret-token
kubectl get secret/apm-server-quickstart-apm-token -o go-template='{{index .data "secret-token" | base64decode}}'golang测试APM-SERVER通信
1.设置环境变量,
# 服务名,不设置的话,就是代码的文件名
export ELASTIC_APM_SERVICE_NAME=
# apm服务器地址
export ELASTIC_APM_SERVER_URL=http://localhost:8200
# 我们上一步拿到的token
export ELASTIC_APM_SECRET_TOKEN=
# 可以设置也可以不设置,用于标识环境的,类似标签功能
export ELASTIC_APM_ENVIRONMENT=2.编写golang测试代码main.go
package main
import (
"fmt"
"log"
"net/http"
"github.com/gorilla/mux"
"go.elastic.co/apm/module/apmgorilla"
)
func helloHandler(w http.ResponseWriter, req *http.Request) {
fmt.Fprintf(w, "Hello, %s!\n", mux.Vars(req)["name"])
}
func main() {
r := mux.NewRouter()
r.HandleFunc("/hello/{name}", helloHandler)
r.Use(apmgorilla.Middleware())
log.Fatal(http.ListenAndServe(":8000", r))
}
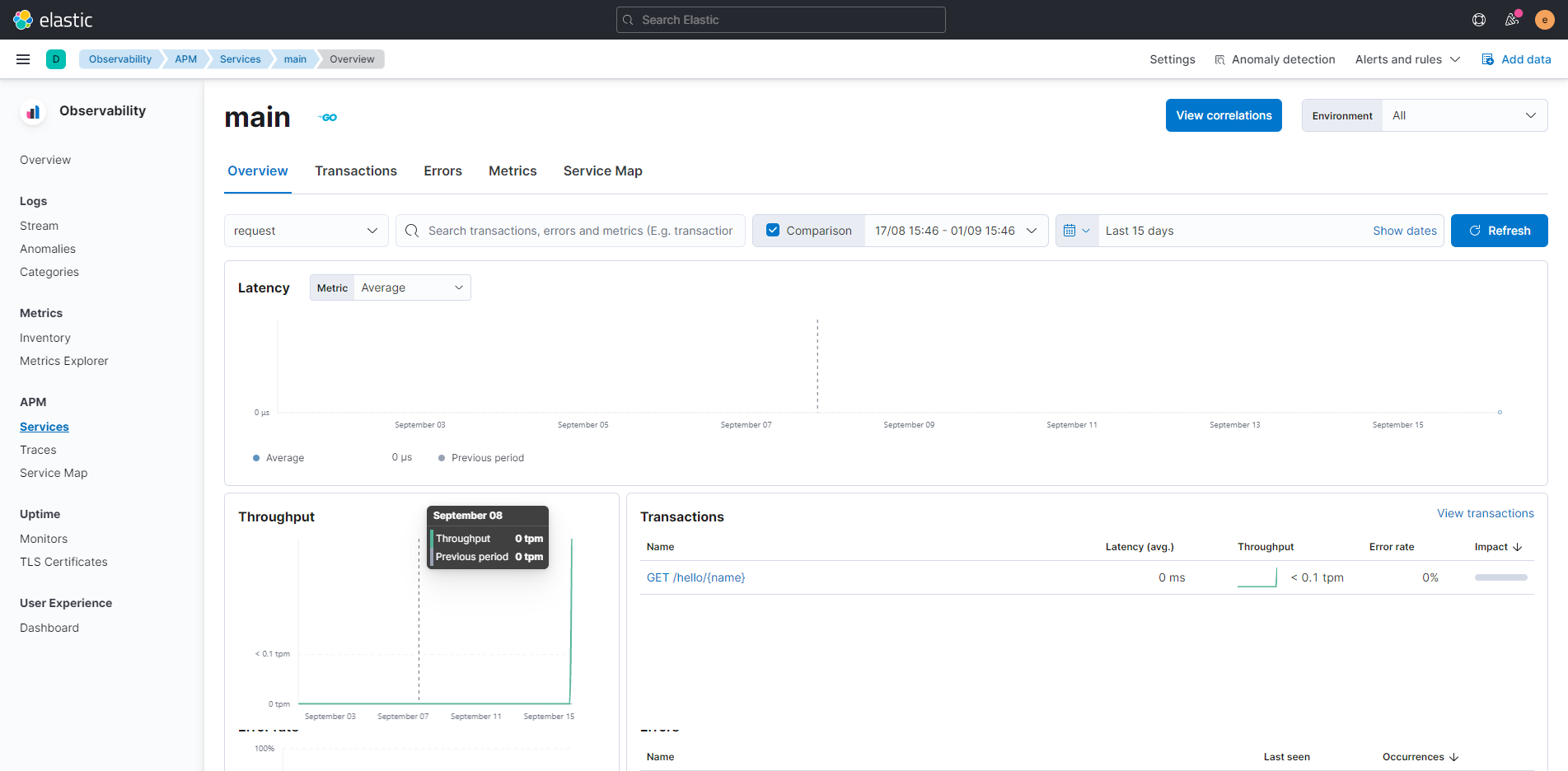
3,在kibana上检查apm的信息,应该会看到一个main的server,有一些数据,如下图所示,证明apm可成功连通