背景需求
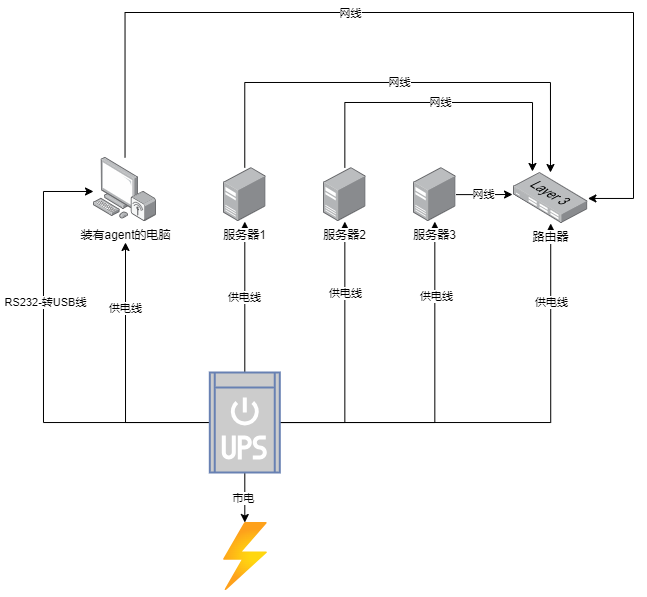
我们有一个常规的网站服务需要部署,并且对外提供https访问,从经济的角度考虑,建议购买阿里云的【容器集群ACK】【网站域名】【NBL负载均衡】【共享带宽包】【云服务器ECS】,如果有文件需求还可以购买【对象存储】【NAS文件系统】等,有静态文件加速需求还可以购买CDN服务,本篇文章我使用最低需求(钱),仅购买3台服务器,组成k8s集群,部署web网站,自动使用acme.sh申请证书,使用外部负载均衡器来打造一个最低限度的高可用生产环境。
忽略的细节
从阿里云官网购买【容器集群ACK】【网站域名】【NBL负载均衡】【共享带宽包】【云服务器ECS】本文忽略,默认读者已购买并添加好,并复制kubeconfig文件到服务器上,kubectl和helm程序已经安装好,接下来直接敲命令
1.安装cert-manager
helm repo add jetstack https://charts.jetstack.io
helm repo update
helm install \
cert-manager jetstack/cert-manager \
--namespace cert-manager \
--create-namespace \
--version v1.15.3 \
--set installCRDs=true2.配置cert-manager所需要的阿里云dns挑战
安装阿里云dns挑战所对应的webhook
helm repo add cert-manager-alidns-webhook https://devmachine-fr.github.io/cert-manager-alidns-webhook
helm repo update
helm install alidns-webhook cert-manager-alidns-webhook/alidns-webhook添加alidns-secret.yaml 文件,注意这里的access-key和secret-key是要通过阿里云的accesskey功能去获取的,获取之后,通过echo命令获取base64加密后的文本,填入yaml文件中
echo -n "原始密钥" | base64
# alidns-secret.yaml 文件
apiVersion: v1
kind: Secret
metadata:
name: alidns-secret
namespace: cert-manager
data:
access-key: base64加密后的
secret-key: base64加密后的kubectl apply -f alidns-secret.yaml
添加letsencrypt-staging.yaml文件,注意不要修改groupName,因为我上面helm install alidns-webhook的时候使用的默认参数里的groupName是example.com,一定要修改groupName的话,需要两边同步修改
apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: letsencrypt-staging
spec:
acme:
email: 357244849@qq.com
server: https://acme-v02.api.letsencrypt.org/directory
privateKeySecretRef:
name: letsencrypt-staging-account-key
solvers:
- dns01:
webhook:
groupName: example.com
solverName: alidns-solver
config:
region: ""
accessKeySecretRef:
name: alidns-secret
key: access-key
secretKeySecretRef:
name: alidns-secret
key: secret-keykubectl apply -f letsencrypt-staging.yaml
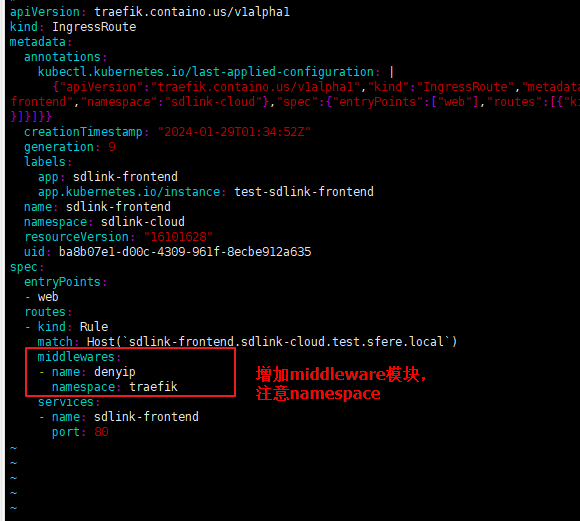
添加Certificate.yaml文件,这一步完成后,手动去阿里云的域名解析里添加对应的cname解析了,记录值填负载均衡器给到的域名,一般是nlb-xxxx.地域.nlb.aliyuncs.com
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: hello-com
namespace: traefik
spec:
# The secretName will store certificate content
secretName: hello-com-tls
dnsNames:
- "*.hello.com"
- "ops.hello.com"
issuerRef:
name: letsencrypt-staging
kind: ClusterIssuerkubectl apply -f Certificate.yaml3.安装traefik并关联对应的证书和负载均衡器
1.编辑一个values-traefik.yaml文件,可以参考我下面的配置,
providers:
kubernetesCRD:
allowCrossNamespace: true
kubernetesIngress:
publishedService:
enabled: true # 让 Ingress 的外部 IP 地址状态显示为 Traefik 的 LB IP 地址
service:
enabled: true
loadBalancerClass: alibabacloud.com/nlb
annotations:
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-id: "NLB的ID" # 关联阿里云NLB负载均衡器的ID。
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-force-override-listeners: "true"
spec:
externalTrafficPolicy: Local
# 这里不加的话,80和 443 会报没有权限
securityContext:
capabilities:
add:
- NET_BIND_SERVICE
runAsNonRoot: false
runAsUser: 0
updateStrategy:
# -- Customize updateStrategy: RollingUpdate or OnDelete
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 0
ports:
web:
port: 80
expose:
default: true
exposedPort: 80 # 对外的 HTTP 端口号,使用标准端口号在国内需备案
redirectTo:
port: websecure
websecure:
port: 443
expose:
default: true
exposedPort: 443 # 对外的 HTTPS 端口号,使用标准端口号在国内需备案
logs:
access:
enabled: true
deployment:
enabled: true
replicas: 3
ingressRoute:
dashboard:
enabled: true
matchRule: Host(`traefik.hello.com`) && (PathPrefix(`/dashboard`) || PathPrefix(`/api`))
entryPoints: ["websecure"]
middlewares:
- name: traefik-dashboard-auth
extraObjects:
- apiVersion: v1
kind: Secret
metadata:
name: traefik-dashboard-auth-secret
type: kubernetes.io/basic-auth
stringData:
username: hello
password: thankyou
- apiVersion: traefik.io/v1alpha1
kind: Middleware
metadata:
name: traefik-dashboard-auth
spec:
basicAuth:
secret: traefik-dashboard-auth-secret
# 关联cert-manager设置的秘钥
tlsStore:
default:
defaultCertificate:
secretName: hello-com-tls
helm repo add traefik https://helm.traefik.io/traefik
helm repo update
helm upgrade --install traefik -n traefik -f values-traefik.yaml traefik/traefik安装完成后,使用kubectl get svc -n traefik就能看到生成的loadbalancer了,通过阿里云控制台也可以看到网络型负载均衡器里面自动创建了对应的监听和服务器组,如需验证部署后的效果,可以用浏览器访问https://traefik.hello.com/dashboard 进行测试