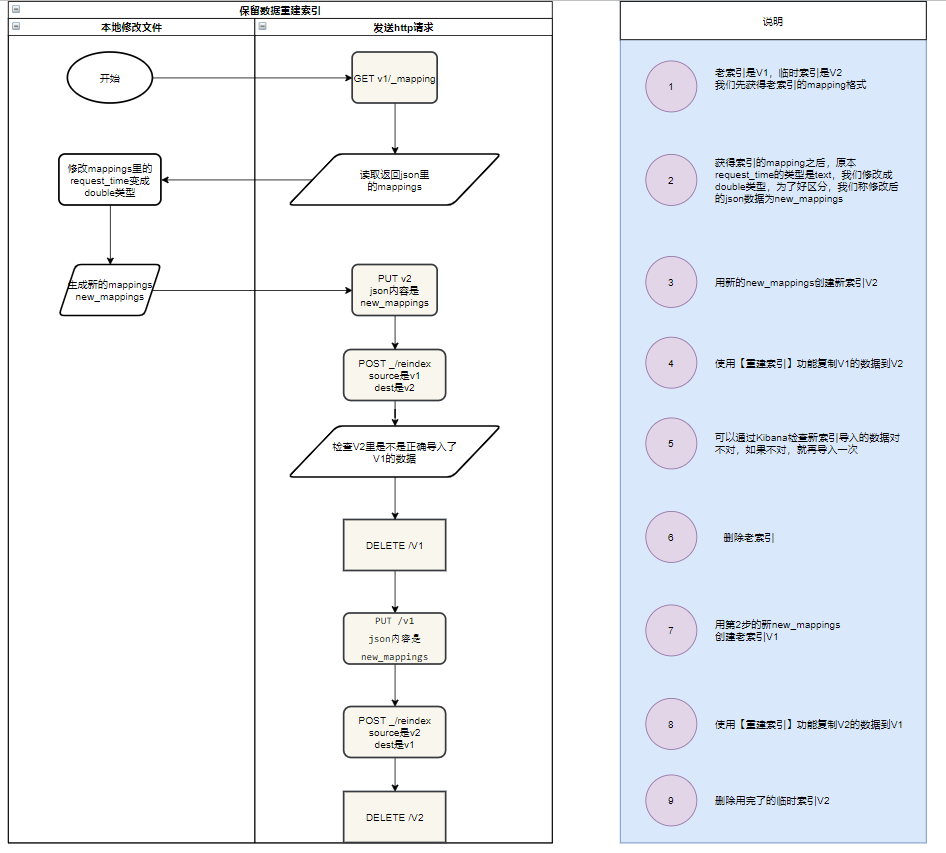
需求:
小程序后台用的sqllite数据库,刚开始用的时候,没有考虑多线程,而且当时因为数据量少,没有出现过多线程查询报错,现在数据量大了。多线程查询经常报错
ProgrammingError: Recursive use of cursors not allowed.
就是这个头疼的错。在网上查了大量的资料,要么就是加lock=threading.lock(),要么就是加sleep.终究还是解决不了问题。
刚好最近在网上看了一个小哥哥用Queue来解决这个问题。我改进了一下。目前能够使用该方法进行增删改查。查询出来的结果以字典的形式返回。
话不多说,下面上代码
代码
# -*- coding: UTF-8 -*-
import sqlite3
import time
from Queue import Queue
from threading import Thread
def sqllite_escape(key_word):
key_word = key_word.encode("utf-8")
key_word = key_word.replace("'", "''")
return key_word
class SelectConnect(object):
'''
只能用来查询
'''
def __init__(self):
# isolation_level=None为智能提交模式,不需要commit
self.conn = sqlite3.connect('resource/data.ta', check_same_thread=False, isolation_level=None)
self.conn.execute('PRAGMA journal_mode = WAL')
cursor = self.conn.cursor()
cursor.execute('PRAGMA synchronous=OFF')
self.conn.text_factory = str
# 把结果用元祖的形式取出来
self.curosr = self.conn.cursor()
self.conn.row_factory = self.dict_factory
# 把结果用字典的形式取出来
self.curosr_diction = self.conn.cursor()
def commit(self):
self.conn.commit()
def dict_factory(self, cursor, row):
d = {}
for idx, col in enumerate(cursor.description):
d[col[0]] = row[idx]
return d
def close_db(self):
# self.curosr.close()
self.conn.close()
class SqliteMultithread(Thread):
"""
Wrap sqlite connection in a way that allows concurrent requests from multiple threads.
This is done by internally queueing the requests and processing them sequentially
in a separate thread (in the same order they arrived).
"""
def __init__(self, filename, autocommit, journal_mode):
super(SqliteMultithread, self).__init__()
self.filename = filename
self.autocommit = autocommit
self.journal_mode = journal_mode
self.reqs = Queue() # use request queue of unlimited size
self.setDaemon(True) # python2.5-compatible
self.running = True
self.start()
def dict_factory(self, cursor, row):
# field = [i[0] for i in cursor.description]
# value = [dict(zip(field, i)) for i in records]
d = {}
for idx, col in enumerate(cursor.description):
d[col[0]] = row[idx]
return d
def run(self):
if self.autocommit:
conn = sqlite3.connect(self.filename, isolation_level=None, check_same_thread=False)
else:
conn = sqlite3.connect(self.filename, check_same_thread=False)
conn.execute('PRAGMA journal_mode = %s' % self.journal_mode)
conn.text_factory = str
cursor = conn.cursor()
cursor.execute('PRAGMA synchronous=OFF')
conn.row_factory = self.dict_factory
curosr_diction = conn.cursor()
curosr_diction.execute('PRAGMA synchronous=OFF')
# 把结果用字典的形式取出来
while self.running:
req, arg, res = self.reqs.get()
if req == '--close--':
break
elif req == '--commit--':
conn.commit()
else:
# print(arg)
curosr_diction.execute(req, arg)
# if res:
# for rec in cursor:
# res.put(rec)
# res.put('--no more--')
if res:
res.put(curosr_diction.fetchall())
if self.autocommit:
conn.commit()
conn.close()
def execute(self, req, arg=None, res=None):
"""
`execute` calls are non-blocking: just queue up the request and return immediately.
"""
self.reqs.put((req, arg or tuple(), res))
def executemany(self, req, items):
for item in items:
self.execute(req, item)
def select_all_dict(self, req, arg=None):
'''
直接返回一个list
:param req:
:param arg:
:return:
'''
res = Queue() # results of the select will appear as items in this queue
self.execute(req, arg, res)
rec = res.get()
return rec
def select_one_dict(self, req, arg=None):
'''
直接返回list里的第一个元素,并且以字典展示
:param req:
:param arg:
:return:
'''
res = Queue() # results of the select will appear as items in this queue
self.execute(req, arg, res)
rec = res.get()
if len(rec) != 0:
rec = rec[0]
else:
rec = None
return rec
def commit(self):
self.execute('--commit--')
def close(self):
self.execute('--close--')
class Cursor(object):
'''
以元祖的形式查询出数据
'''
def __init__(self):
old_con = SelectConnect()
self.conn = old_con.conn
self.curosr = old_con.curosr
self.curosr2 = SqliteMultithread('resource/data.ta', autocommit=True, journal_mode="WAL")
def execute(self, string, *args):
try:
if string.startswith('select'):
return self.curosr.execute(string, *args)
else:
return self.curosr2.execute(string, *args)
except Exception:
print("失败一次")
print(string)
time.sleep(0.1)
self.execute(string, *args)
def executescript(self, string):
try:
self.curosr.executescript(string)
except Exception:
print("失败一次")
print(string)
time.sleep(0.1)
self.executescript(string)
def fetchall(self):
return self.curosr.fetchall()
def fetchone(self):
return self.curosr.fetchone()
def rowcount(self):
return self.curosr.rowcount
def close(self):
self.curosr2.running = False
self.curosr.close()
self.conn.close()
class Curosrdiction(object):
'''
以字典的形式查询出数据,建议全部用这种。
'''
def __init__(self):
old_con = SelectConnect()
self.conn = old_con.conn
self.curosrdiction = old_con.curosr_diction
self.curosr2 = SqliteMultithread('resource/data.ta', autocommit=True, journal_mode="WAL")
def execute(self, string, *args):
try:
if string.startswith('select'):
return self.curosrdiction.execute(string, *args)
else:
return self.curosr2.execute(string, *args)
except Exception:
print("失败一次")
print(string)
time.sleep(0.1)
self.execute(string, *args)
def executescript(self, string):
result = True
try:
self.curosrdiction.executescript(string)
except Exception:
print("失败一次")
# print(string)
time.sleep(0.1)
# self.executescript(string)
result = False
return result
def fetchall(self):
return self.curosrdiction.fetchall()
def fetchone(self):
return self.curosrdiction.fetchone()
def rowcount(self):
return self.curosrdiction.rowcount
def select_all_dict(self, string, *args):
return self.curosr2.select_all_dict(string, *args)
def select_one_dict(self, string, *args):
return self.curosr2.select_one_dict(string, *args)
def close(self):
self.curosr2.running = False
self.curosrdiction.close()
self.conn.close()
def commit(self):
self.conn.commit()
self.curosr2.commit()
# curosr = Cursor()
curosr_diction = Curosrdiction()
def commit():
curosr_diction.commit()
def close_db():
# curosr.close()
curosr_diction.close()