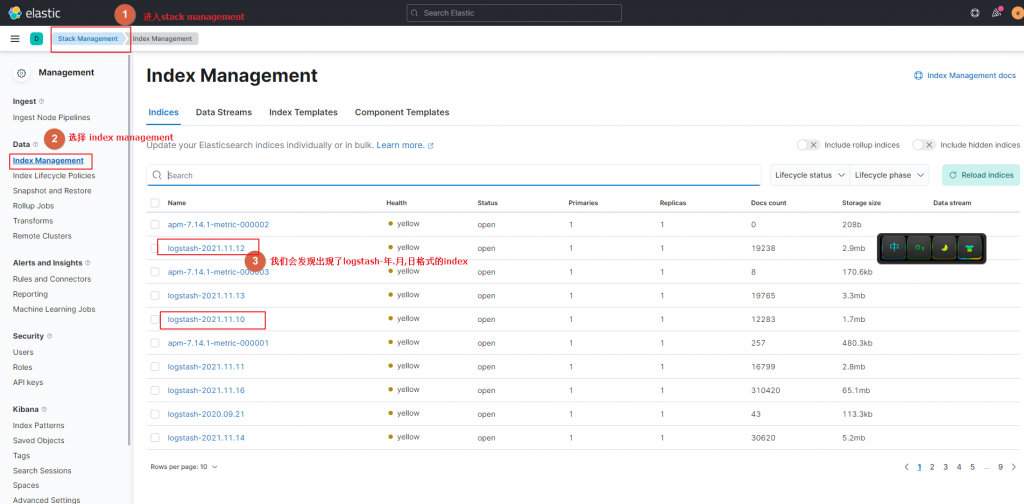
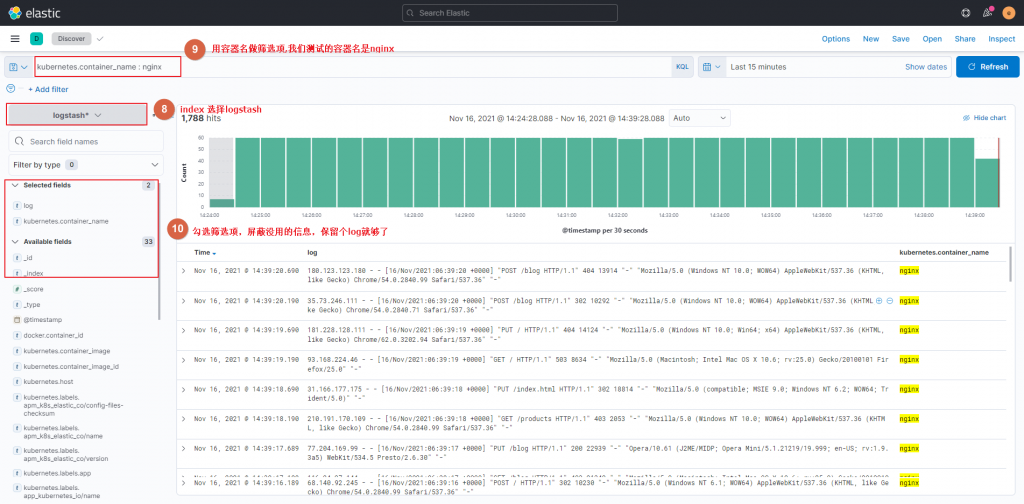
背景&架构
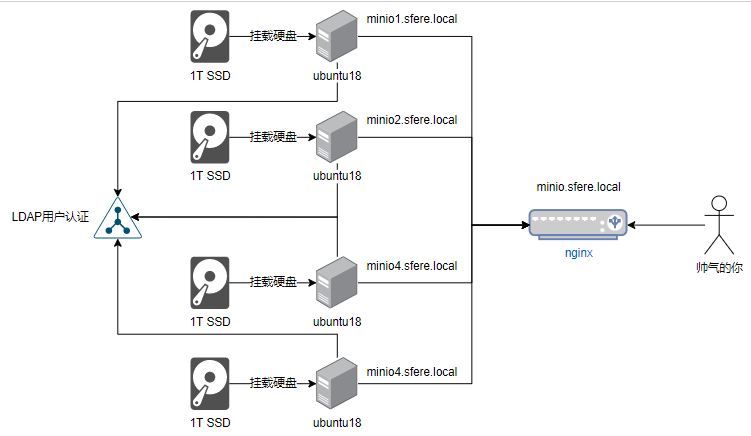
因为单机的minio无法扩充节点,无法使用版本功能,于是我们边开始使用minio的分布式版本,minio的分布式版本可以使用docker、kubernetes、裸机三种方式,这里我们使用裸机安装,架构如下图所示
1准备工作
4台ubuntu18的电脑,每台电脑的系统,CPU,内存,硬盘空间大小均一致。给minio用的硬盘需使用XFS格式化。挂载给minio用的硬盘到/mnt/disk目录。分别按顺序配置了4个域名
minio1.sfere.local minio2.sfere.local minio3.sfere.local minio4.sfere.local
编者注:这里我与官网略有不同,我每个服务器只有一块硬盘给挂载,官网是每个服务器给4块硬盘挂载
1个安装了nginx的服务器,域名是minio.sfere.local
编者注:如果你没有域名,你可以在这5台机器里的hosts文件里把5个地址加上,再在你的测试机器的hosts里上加上这5个地址
2.安装minio程序(4台电脑均进行一样的操作)
1.进入官网的下载链接,下载一个最新的deb文件https://dl.min.io/server/minio/release/linux-amd64/
例如我下载的 是 https://dl.min.io/server/minio/release/linux-amd64/minio_20211124231933.0.0_amd64.deb
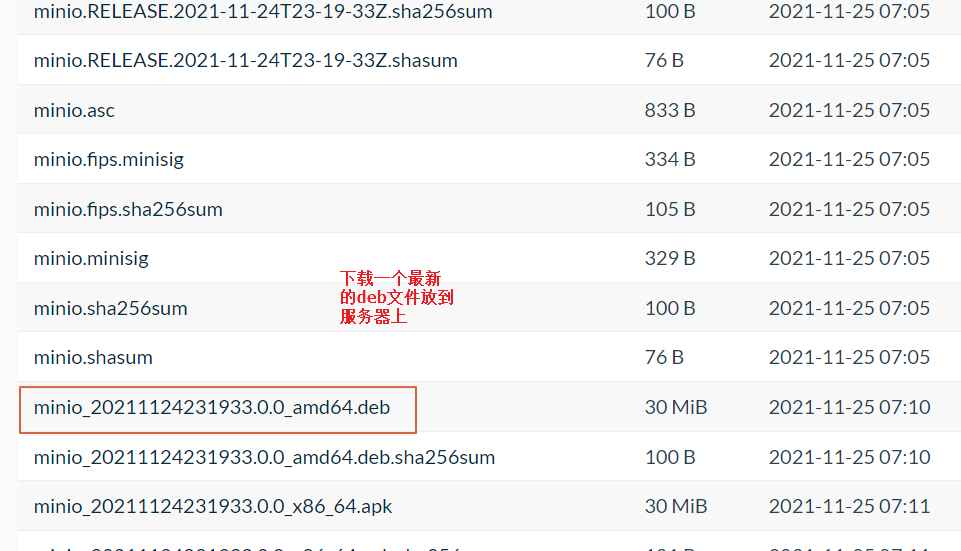
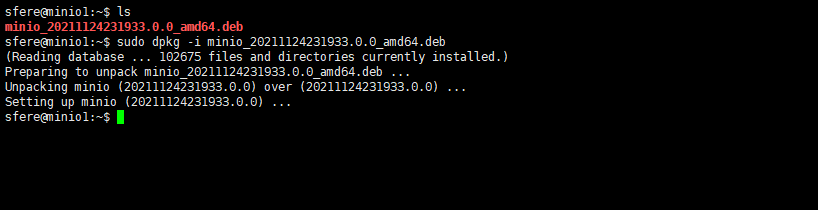
2.把最新文件放到4台服务器上,使用dpkg命令安装
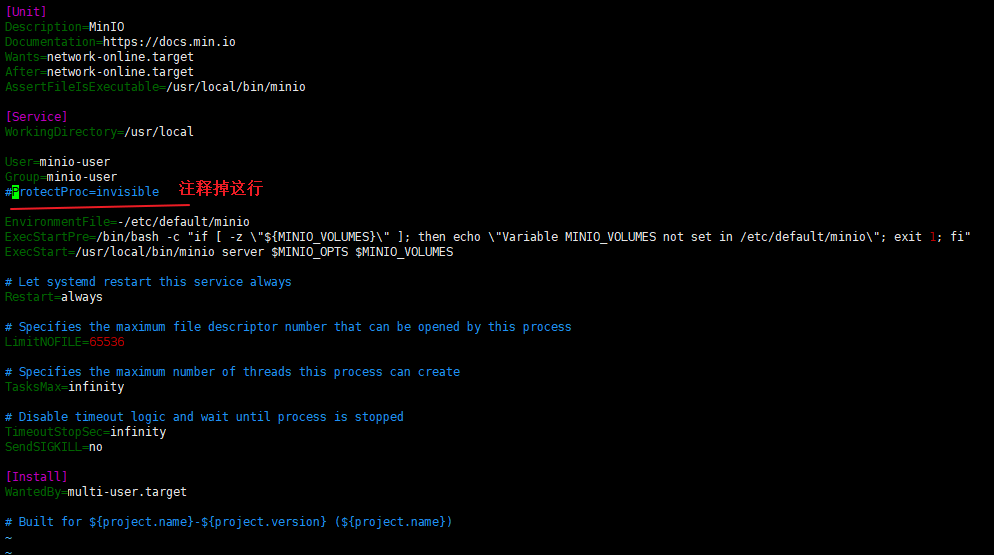
3.sudo vi /etc/systemd/system/minio.service 注释掉ProtectProc=invisible 。这个是kernel 5.8之后才加入的,我们的ubuntu18系统不支持
4.添加minio-user用户和用户组。注意:此处与官网略有不同,官网打错字了把minio-user打成了miniouser
sudo groupadd -r minio-user
sudo useradd -M -r -g minio-user minio-user
sudo chown minio-user:minio-user /mnt/disk5.创建环境变量文件
sudo nano /etc/default/minio
# Set the hosts and volumes MinIO uses at startup
# The command uses MinIO expansion notation {x...y} to denote a
# sequential series.
#
# The following example covers four MinIO hosts
# with 4 drives each at the specified hostname and drive locations.
MINIO_VOLUMES="http://minio{1...4}.sfere.local/mnt/disk/minio"
# Set all MinIO server options
#
# The following explicitly sets the MinIO Console listen address to
# port 9001 on all network interfaces. The default behavior is dynamic
# port selection.
MINIO_OPTS="--console-address :9001"
# Set the root username. This user has unrestricted permissions to
# perform S3 and administrative API operations on any resource in the
# deployment.
#
# Defer to your organizations requirements for superadmin user name.
MINIO_ROOT_USER=minioadmin
# Set the root password
#
# Use a long, random, unique string that meets your organizations
# requirements for passwords.
MINIO_ROOT_PASSWORD=sfere!lzw!2021
# Set to the URL of the load balancer for the MinIO deployment
# This value *must* match across all MinIO servers. If you do
# not have a load balancer, set this value to to any *one* of the
# MinIO hosts in the deployment as a temporary measure.
# nginx服务器地址
MINIO_SERVER_URL="http://minio.sfere.local"
MINIO_IDENTITY_LDAP_TLS_SKIP_VERIFY=on
MINIO_IDENTITY_LDAP_SERVER_INSECURE=on
MINIO_IDENTITY_LDAP_STS_EXPIRY=24h
MINIO_IDENTITY_LDAP_SERVER_ADDR=${LDAP域名}
MINIO_IDENTITY_LDAP_LOOKUP_BIND_DN=${LDAP只读账户}
MINIO_IDENTITY_LDAP_LOOKUP_BIND_PASSWORD=${LDAP只读账户的密码}
MINIO_IDENTITY_LDAP_USER_DN_SEARCH_BASE_DN=${LDAP用户搜索域}
MINIO_IDENTITY_LDAP_USER_DN_SEARCH_FILTER=(&(objectClass=inetOrgPerson)(uid=%s))
MINIO_IDENTITY_LDAP_GROUP_SEARCH_BASE_DN=${LDAP组搜索域}
MINIO_IDENTITY_LDAP_GROUP_SEARCH_FILTER=(&(objectclass=groupOfUniqueNames))6. 运行minio服务,检查运行是否成功
sudo systemctl start minio.service
sudo systemctl status minio.service
journalctl -f -u minio.servicenginx配置
在/etc/nginx/conf.d目录下添加一个minio.conf
upstream minio {
server minio1.sfere.local:9000;
server minio2.sfere.local:9000;
server minio3.sfere.local:9000;
server minio4.sfere.local:9000;
}
upstream console {
ip_hash;
server minio1.sfere.local:9001;
server minio2.sfere.local:9001;
server minio3.sfere.local:9001;
server minio4.sfere.local:9001;
}
server {
listen 80;
listen [::]:80;
server_name minio.sfere.local;
# To allow special characters in headers
ignore_invalid_headers off;
# Allow any size file to be uploaded.
# Set to a value such as 1000m; to restrict file size to a specific value
client_max_body_size 0;
# To disable buffering
proxy_buffering off;
location / {
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_connect_timeout 300;
# Default is HTTP/1, keepalive is only enabled in HTTP/1.1
proxy_http_version 1.1;
proxy_set_header Connection "";
chunked_transfer_encoding off;
proxy_pass http://minio;
}
}
server {
listen 9001;
listen [::]:9001;
server_name minio.sfere.local;
# To allow special characters in headers
ignore_invalid_headers off;
# Allow any size file to be uploaded.
# Set to a value such as 1000m; to restrict file size to a specific value
client_max_body_size 0;
# To disable buffering
proxy_buffering off;
location / {
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-NginX-Proxy true;
# This is necessary to pass the correct IP to be hashed
real_ip_header X-Real-IP;
proxy_connect_timeout 300;
# To support websocket
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
chunked_transfer_encoding off;
proxy_pass http://console;
}
}使用mc客户端添加ldap超管,普通用户
docker run --rm -it --entrypoint=/bin/sh minio/mc
mc config host add minio http://minio.sfere.local minioadmin 'sfere!lzw!2021' --api S3v4
mc admin policy list minio
mc admin policy set minio consoleAdmin user=cn=李镇伟,ou=test-department,ou=NJ-Dev,ou=SFERE-RD,dc=sfere-elec,dc=com
mc admin policy set minio readwrite group=cn=jira-software-users,dc=sfere-elec,dc=com
mc admin policy set minio consoleAdmin group=cn=超级用户,dc=sfere-elec,dc=com访问页面
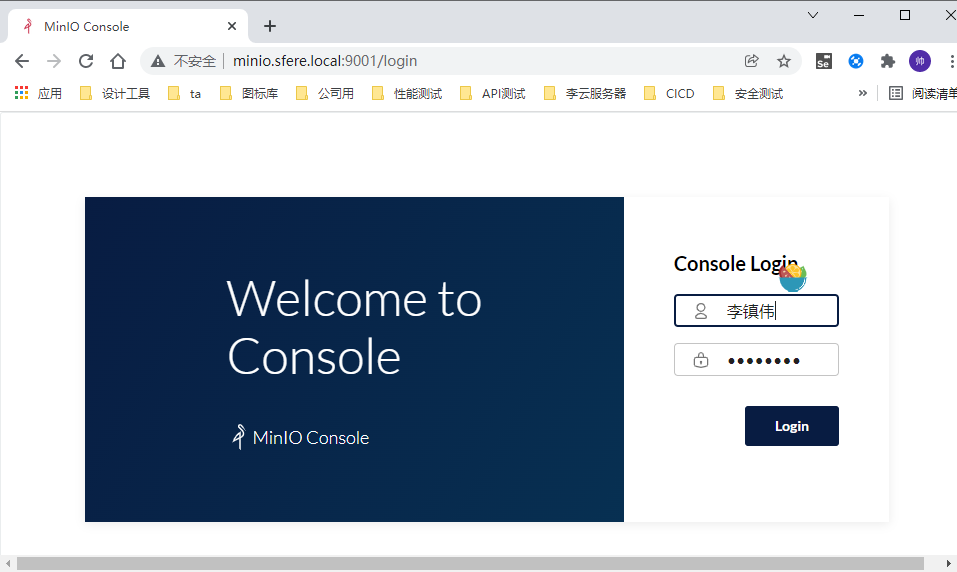
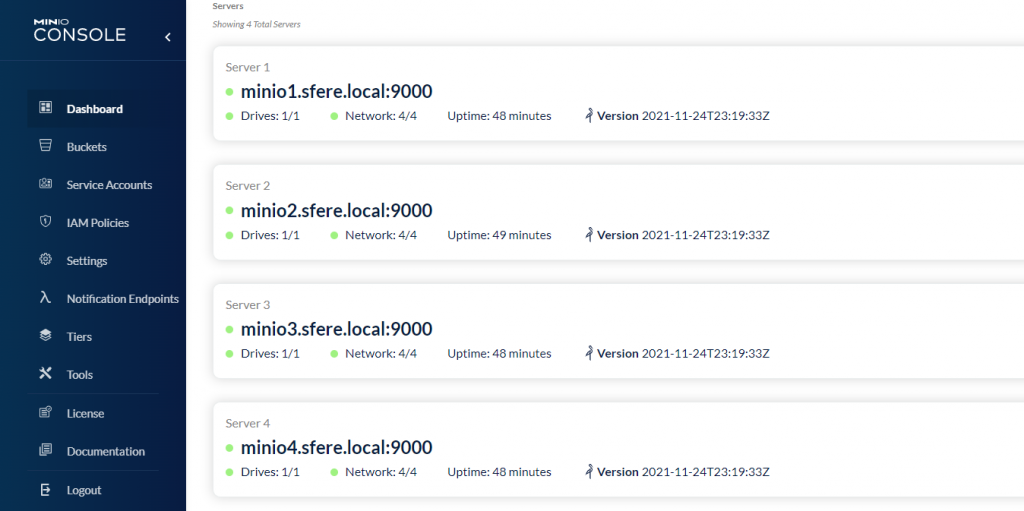
访问http://minio.sfere.local/ 会自动跳转到http://minio.sfere.local:9001/login
参考文章
https://docs.min.io/minio/baremetal/installation/deploy-minio-distributed.html