Elasticsearch重建索引,收集nginx日志,以request_time为指标分析接口响应时间
起因
filebeat采集nginx的日志,以json格式解析后传入elasticsearch,全部字段都是text格式,我们需要把request_time变成double格式才能使用聚合搜索request_time的最大值.
但是elasticsearch的index一旦建立好之后,字段只能新增,不能修改,所以要修改request_time的数据类型,只能重建索引。
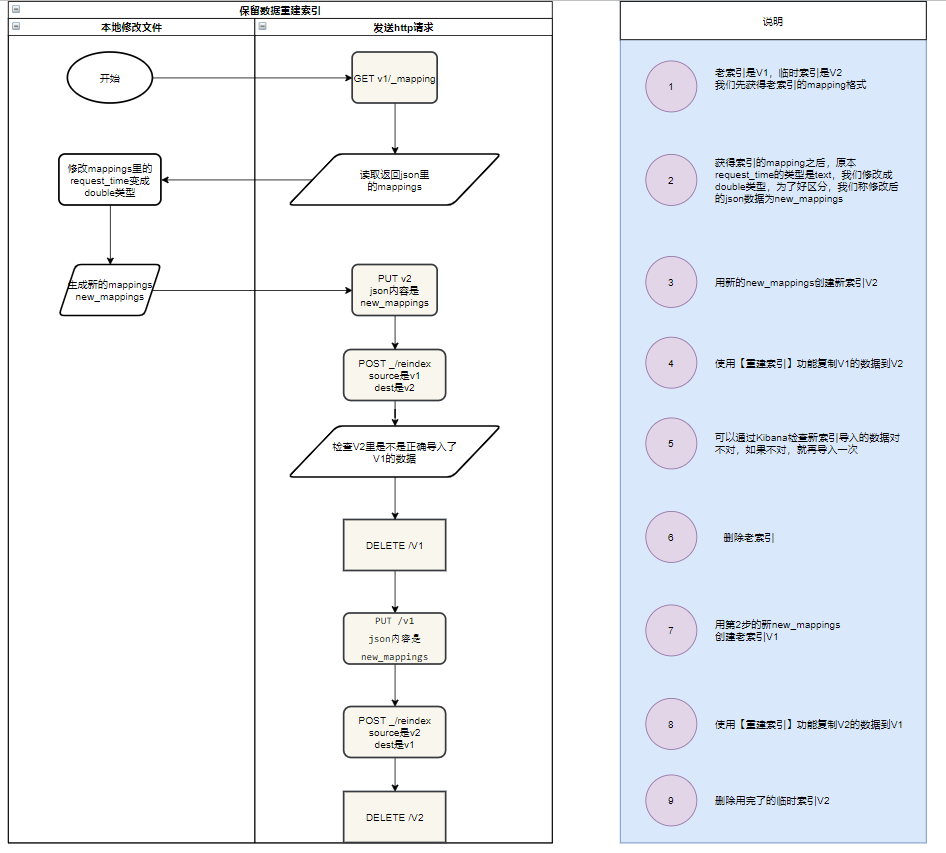
我们的步骤是:1.获得老索引的mapping信息,2.用这个mapping信息新建一个索引 3.用reindex方法,把老索引的数据迁移到新索引 4.确认新索引数据迁移成功,5.删除老索引 6.获得出新索引的mapping,7.使用新索引的mapping创建老索引。8.把新索引的数据倒回老索引 9.删除老索引
假设老索引:V1
临时索引:V2
nginx统计接口路径:path字段
nginx统计响应时间:request_time字段
流程图与说明
python代码
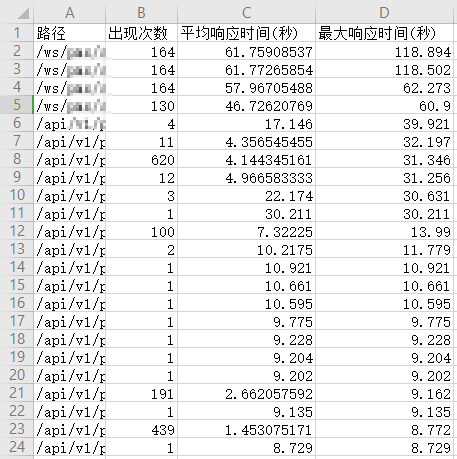
根据path,聚合查询出响应最大时间和平均时间,保留最大响应时间前500个到csv文件里
#
# created by zhenwei.Li at 2020/11/3 17:50
#
# filename : example4.py
# description :
import csv
import json
import requests
if __name__ == '__main__':
send_json = {
"query": {
"bool": {
"must": [
{
"range": {
"@timestamp": {
"gte": 1533556800000,
"lte": 1604470685934
}
}
}
]
}
},
"size": 0,
"aggs": {
"Job_gender_stats": {
"terms": {
"field": "path.keyword",
"size": 500,
"order": {
"max_request_time": "desc"
}
},
"aggs": {
"max_request_time": {
"max": {
"field": "request_time"
}
},
"avg_request_time": {
"avg": {
"field": "request_time"
}
}
}
}
}
}
res = requests.post(url="http://192.168.0.174:32164/192.168.0.67-eiop-frontend/_search", json=send_json)
print(json.dumps(res.json()['aggregations']['Job_gender_stats']['buckets'], sort_keys=True, indent=4))
buckets = res.json()['aggregations']['Job_gender_stats']['buckets']
file_handle = open('research.csv', 'w', encoding='utf-8', newline='' "")
# 2. 基于文件对象构建 csv写入对象
csv_writer = csv.writer(file_handle)
# 3. 构建列表头
csv_writer.writerow(["路径", "出现次数", "平均响应时间(秒)", "最大响应时间(秒)"])
for item in buckets:
csv_writer.writerow(
[item['key'], item['doc_count'], item['avg_request_time']['value'], item['max_request_time']['value']])
# 5. 关闭文件
file_handle.close()效果图